
Khi sử dụng các ngôn ngữ như Python hoặc Javascript, hay gõ các biểu thức toán học trong Matlab hay LaTeX, có bao giờ bạn tự hỏi trình thông dịch làm cách nào để bóc tách và hiểu được những câu lệnh đó chưa? Mình thì có.
Cơ duyên đưa mình đến với chủ đề Parser bắt đầu từ một dự án cần tính toán các biểu thức toán học (từ các phép tính cơ bản đến phức tạp như , , hay luỹ thừa ). Bài toán cốt lõi được đặt ra là: làm sao để biến một chuỗi ký tự văn bản thuần tuý thành một cấu trúc dữ liệu mà máy tính có thể hiểu được và thực thi đúng thứ tự.
Trong quá trình tìm kiếm giải pháp, mình nhận ra rào cản lớn nhất khi parse biểu thức toán học chính là độ ưu tiên toán tử (Operator precedence). Thay vì sa lầy vào các bộ quy tắc ngữ pháp cồng kềnh, khó cài đặt và scale thì mình đã tìm kiếm một giải pháp đơn giản hơn nhưng lại hiệu quả và thanh lịch hơn hẳn: Pratt Parser (Top-Down Operator Precedence Parsing).
Pratt Parser
Pratt Parser được anh tui, Vaughan Pratt giới thiệu từ tận nằm 1973. Nghe thì cái thuật này nó cổ vãi ra nhưng cũng đừng vì vậy mà bỏ qua nó, tư tưởng của thuật toán này thực chất lại rất hiện đại và gọn gàng.
Như mình đã đề cập ở trên, rào cản lớn nhất khi parse một biểu thức toán học là độ ưu tiên toán tử. Lấy ví dụ với biểu thức .
Làm sao để máy tính biết phải gom và lại tính trước, thay vì cứ chạy tuột từ trái sang phải thành , rồi ?
Nếu bạn sử dụng các phương pháp phân tích cú pháp truyền thống (Như phương pháp đệ quy chẳng hạn) thì bạn sẽ phải thiết kế một bộ xử lý ngữ pháp rất cồng kềnh. Hàm xử lý phép cộng sẽ phải gọi hàm xử lý phép nhân, hàm nhân lại gọi đến hàm ngoặc... vâng vâng và mây mây. Cú pháp của bạn càng nhiều thì các hàm đệ quy càng lồng vào nhau khiến bộ parser của bạn cực kỳ rối rắm và khó bảo trì.
Pratt Parser lại chọn một cách tiếp cận khác. Thay vì quản lý bằng một bộ quy tắc ngữ pháp chung chung, Pratt Parser gắn logic và Binding Power (Độ ưu tiên) vào trực tiếp từng token.
Bạn cứ tưởng tượng một toán tử là một cục nam châm. Dấu * có từ tính mạnh hơn dấu +. Khi parser đọc biểu thức từ trái sang phải, thằng nào có lực hút mạnh hơn thì nó sẽ "giật" lấy con số ở cạnh nó để xử lý trước.
Nhờ cơ chế gom nhóm dựa trên độ ưu tiên này mà từ một chuỗi biểu thức ban đầu, Pratt Parser có thể dễ dàng bóc tách và dựng lên một Cây cú pháp trừu tượng (AST - Abstract Syntax Tree) chuẩn xác chỉ bằng một vòng while cơ bản:
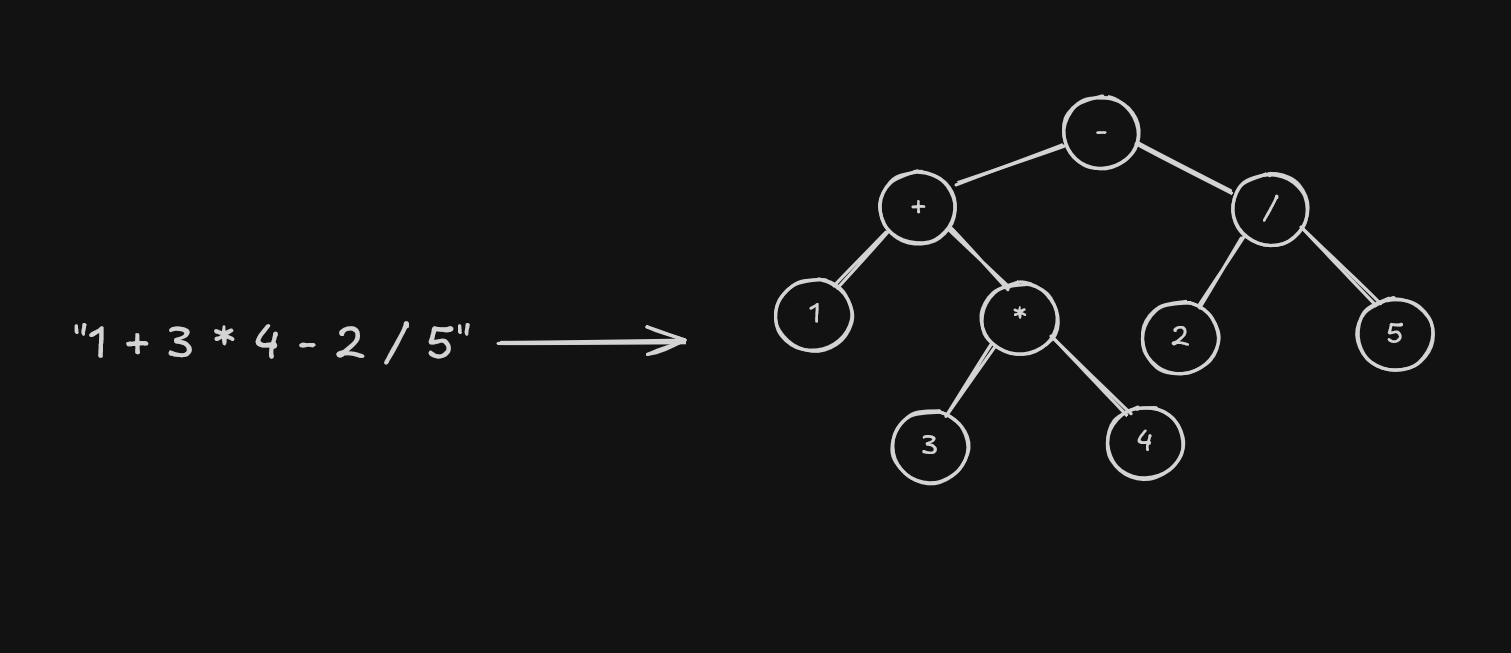 (Cây AST mô tả thứ tự thực thi: Các note sâu hơn thì tính trước)
(Cây AST mô tả thứ tự thực thi: Các note sâu hơn thì tính trước)
Mục tiêu thực hiện
Vì mình là một người phải vừa làm vừa học thì mới thấm cũng như thể hiện sức mạnh của Pratt parser, mình sẽ viết một bộ parser cho chiếc máy tính nhỏ nhắn bằng CLI như một case study cho bài viết
Viên gạch đầu tiên
Trước khi bóc tách ngữ pháp để dựng nên cây AST, chuỗi văn bản đầu vào cần được chuyển đổi thành một định dạng dễ thao tác hơn. Bước này được đảm nhiệm bởi Lexer (Bộ phân tích từ vựng).
Nhiệm vụ của Lexer rất đơn giản: Đọc chuỗi ký tự từ trái sang phải, bỏ qua các khoảng trắng thừa và gom nhóm chúng thành những đơn vị có nghĩa nhỏ nhất, gọi là Token.
Với biểu thức 1 + 3 * 4 - 2 / 5, Lexer sẽ phân loại các ký tự thành Token đại diện cho Giá trị (ATOM) hoặc Toán tử (OPERATOR):
1 | + | 3 | * | 4 | - | 2 | / | 5
ATOM | OPERATOR | ATOM | OPERATOR | ATOM | OPERATOR | ATOM | OPERATOR | ATOMDựa vào đó, ta có thể xây dựng bộ Lexer như sau. Trước tiên ta định nghĩa một Token:
type TokenType int
const (
ILLEGAL TokenType = iota
EOF
ATOM
OP
)
type Token struct {
Type TokenType
Literal string
}Bây giờ ta tiến hành cài đặt Lexer
type Lexer struct {
source string
pos int
readPos int
ch byte
}
func (l *Lexer) readChar() {
if l.readPos >= len(l.source) {
l.ch = 0
} else {
l.ch = l.source[l.readPos]
}
l.pos = l.readPos
l.readPos++
}
func (l *Lexer) skipWhitespace() {
for unicode.IsSpace(rune(l.ch)) {
l.readChar()
}
}
func New(input string) *Lexer {
l := &Lexer{source: input}
l.readChar()
return l
}Tại sao chúng ta lại cần
posvàreadPos? Bởi vì đây là kỹ thuật giúp Lexer có thể "nhìn trước" ký tự tiếp theo mà không làm xô lệch con trỏ hiện tại. Nó nó rất hữu ích nếu sau này bạn muốn thêm các toán tử như<=,==hay>=.
Hàm
readChar()sẽ làm nhiệm vụ nạp ký tự vào biến ch và tịnh tiến các con trỏ hiện tại lên một bước.
Special Week
Khi bộ khung của Lexer đã hoàn chỉnh, mảnh ghép tiếp theo mà ta cần là một con Special Week có thể "hốc" các chuỗi đầu vào thành các Token. Đó chính là nhiệm vụ của hàm NextToken()
func (l *Lexer) NextToken() Token {
l.skipWhitespace()
if l.ch == 0 {
return Token{Type: EOF, Literal: "EOF"}
}
// OP
if unicode.IsSymbol(rune(l.ch)) || unicode.IsPunct(rune(l.ch)) {
ch := l.ch
l.readChar()
return Token{Type: OP, Literal: string(ch)}
}
// ATOM
if unicode.IsLetter(rune(l.ch)) || unicode.IsDigit(rune(l.ch)) {
startPos := l.pos
l.readChar()
for unicode.IsLetter(rune(l.ch)) || unicode.IsDigit(rune(l.ch)) {
l.readChar()
}
return Token{Type: ATOM, Literal: l.source[startPos:l.pos]}
}
// If we reach here, it's an illegal character
ch := l.ch
l.readChar()
return Token{Type: ILLEGAL, Literal: string(ch)}
}Hiểu đơn giản là mỗi lần Parser gọi NextToken() thì Special Week sẽ "hốc" một hoặc một vài ký tự của chuỗi source, kiểm tra xem nó là khoảng trắng (thì bỏ qua), là một con số (thì gom lại thành ATOM), hay là toán tử (thì gán thành OP).
Bên cạnh đó, về bản chất của Pratt Parser là "nhìn trước ngó sau" để quyết định xem có nên gộp toán tử tiếp theo vào cụm hiện tại hay không dựa trên độ ưu tiên, chúng ta cần thêm một hàm hỗ trợ là PeekToken(). Nễu NextToken() là hành động "hốc", lấy ra là bốc hơi thì PeekToken() sẽ chỉ "Ngó" xem, token tiếp theo là gì mà không ảnh hưởng đến token hiện tại.
func (l *Lexer) PeekToken() Token {
currentPos := l.pos
currentReadPos := l.readPos
currentCh := l.ch
token := l.NextToken()
l.pos = currentPos
l.readPos = currentReadPos
l.ch = currentCh
return token
}Sau khi Lexer hoàn thành nhiệm vụ và cung cấp cho chúng ta một chuỗi Token sạch sẽ, đã đến lúc bước vào phần "nhức não" nhưng cũng thú vị nhất: Triển khai Pratt Parser.
Pratt Parser hoạt động như thế nào
Bí quyết của Pratt Parser xoay quanh hai khái niệm cốt lõi: Độ ưu tiên (Binding Power) và Hai loại hàm phân tích cú pháp.
1. Độ ưu tiên
Hãy tưởng tượng mỗi toán tử là một cục nam châm, các con số là những mẩu sắt. Lực hút của nam châm chính là Độ ưu tiên (Binding Power).
Chúng ta sẽ quy định mức độ mạnh yếu cho chúng. Ví dụ:
- Phép cộng
+và trừ-có lực yếu (bp = 10) - Phép nhân
*và chia/có lực mạnh (bp = 20)
func InfixBP(op string) int {
switch op {
case "+", "-":
return 10
case "*", "/":
return 20
default:
return 0
}
}Khi Parser đi qua biểu thức , nó sẽ làm việc như sau:
nó đọc số 1 đầu tiên
1____Sau đó nó đọc tiếp và thấy dấu +. Parser ghi nhận là vế trái của phép cộng +
1 + ___Để tìm vế phải cho phép +, nó đọc tiếp số
1 + 3 ___Nhưng trước khi quyết định gộp và với nhau, nó dùng hàm PeekToken() để ngó sang phải và thấy dấu *.
1 + 3 * __Lúc này, bởi vì dấu nhân * có độ ưu tiên cao hơn dấu cộng + (), dấu nhân * sẽ giật số làm vế trái của nó. Hệ quả là cụm được gom lại và xử lý trước, sau đó mới trả kết quả về cho phép +
2. Trái tim của Parser
Để thực hiện hoá cái "lực hút" ở trên, Vaughan Pratt đã định nghĩa mọi Token sẽ rơi vào một trong hai nhóm xử lý:
- Hàm Prefix (NUD): Dành cho những Token có thể tự đứng một mình ở đầu biểu thức mà không cần ai đứng trước nó. Ví dụ: một con số nguyên (
1), hoặc dấu trừ trong số âm (-5). Trong hàmParse(), bước kiểm tratoken.Type == lexer.ATOMchính là để xử lý nhóm này. - Hàm Infix (LED): Dành cho những toán tử bắt buộc phải có một giá trị nằm bên trái nó (như
+,-,*,/). Hàm này sẽ nhận cái "vế trái" đã phân tích, tiếp tục đi tìm "vế phải" dựa trên độ ưu tiên.
Bằng cách kết hợp vòng lặp kiểm tra Binding Power và hai khái niệm Prefix/Infix, ta có Pratt Parser:
func (p *Parser) Parse(min_bp int) (*ASTNode, error) {
// 1. NUD
token := p.l.NextToken()
var lhs *ASTNode
if token.Type == lexer.ATOM {
lhs = &ASTNode{Type: LITERAL, Value: token.Literal}
} else {
return nil, fmt.Errorf("unexpected token: %s", token.Literal)
}
// 2. LED
for {
nextToken := p.l.PeekToken()
// Hết file hoặc không phải toán tử thì dừng
if nextToken.Type != lexer.OP || nextToken.Type == lexer.EOF {
break
}
cur_bp := InfixBP(nextToken.Literal)
// Nếu toán tử có độ ưu tiên thấp hơn hoặc bằng mức hiện tại,
// Nó không có quyền nuốt vế trái, do đó không cần tìm sâu thêm.
if cur_bp <= min_bp {
break
}
p.l.NextToken() // consume operator
newNode := &ASTNode{Type: EXPR, Value: nextToken.Literal, Left: lhs}
// Đệ quy đi tìm vế phải với mức ưu tiên mới
rhs, err := p.Parse(cur_bp)
if err != nil {
return nil, err
}
newNode.Right = rhs
lhs = newNode // Cập nhật lại vế trái cho lần lặp tiếp theo
}
return lhs, nil
}Để nó có thể xử lý trong ngoặc hoặc thêm các cú pháp mới dễ dàng hơn, ta có thể tách NUD thành một hàm riêng như sau
func (p *Parser) NUD(token lexer.Token) (*ASTNode, error) {
var left *ASTNode
if token.Type == lexer.ATOM {
left = &ASTNode{Type: LITERAL, Value: token.Literal}
} else if token.Type == lexer.OP && token.Literal == "(" {
// Ép min_bp = 0 là để parser chạy lại từ đầu, nuốt mọi toán tử bên trong ngoặc cho đến khi gặp dấu ')'
expr, err := p.Parse(0)
if err != nil {
return nil, err
}
nextToken := p.l.NextToken()
if nextToken.Literal != ")" {
return nil, fmt.Errorf("expected ')', got: %s", nextToken.Literal)
}
left = expr
} else if token.Type == lexer.OP && token.Literal == "-" {
rhs, err := p.Parse(50) // Toán tử 1 ngôi luôn có độ ưu tiên cao nhất
if err != nil {
return nil, err
}
left = &ASTNode{Type: EXPR, Value: "negate", Right: rhs}
} else {
return nil, fmt.Errorf("unexpected token: %s", token.Literal)
}
return left, nil
}và gọi lại nó trong parser
func (p *Parser) Parse(min_bp int) (*ASTNode, error) {
token := p.l.NextToken()
lhs, err := p.NUD(token)
if err != nil {
return nil, err
}
// ... LED Logic
return lhs, nil
}3. Special Weight và Fatty Cap
Chúng ta biết * mạnh hơn + về độ ưu tiên. Nhưng giả sử sau khi Parser gom xong và , biểu thức của chúng ta sẽ được rút gọn lại thành:
Lúc này, dấu cộng + và dấu trừ - đều có cùng một độ ưu tiên (bp = 10). Vậy cụm sẽ bị hút về bên trái dấu trừ - hay bên phải dấu cộng +? Theo quy tắc toán học, các phép tính này có tính kết hợp trái (Left-Associative), tức là tính từ trái sang phải
Pratt Parser xử lý tình huống này cực kỳ mượt mà chỉ bằng một toán tử so sánh <= trong vòng lặp của hàm Parse()
if curr_bp <= min_bp {
break
}Khi curr_bp nhỏ hơn hoặc bằng min_bp thì vòng lặp sẽ ngừng ngay lập tức, lúc này hàm sẽ kết thúc sớm và trả về cây . Sau đó vòng lập ngoài mới tiếp tục chạy, nuốt lấy dấu trừ - và lấy toàn bộ cụm vừa rồi làm vế trái cho nó
Từ cây AST đến máy tính bỏ túi
Đến đây, chúng ta đã có trong tay một cây AST biễu diễn cấu trúc ngữ pháp chuẩn xác. Tuy nhiên, AST rốt cuộc cũng chỉ là một cấu trúc dữ liệu tĩnh. Để ứng dụng này thực sự trở thành một cái máy tính có thể trả về kết quả, ta cần một cơ chế duyệt qua cây này và thực hiện các phép toán.
Vì AST là một cấu trúc dạng cây, cách tự nhiên và gọn gàng nhất để duyệt nó là sử dụng đệ quy (tính từ các node lá lên node gốc).
Hàm Đánh giá (Evaluator)
Chúng ta sẽ định nghĩa một hàm Eval() gắn thẳng vào struct ASTNode. Hàm này sẽ kiểm tra xem Node hiện tại là một con số (LITERAL), một toán tử 1 ngôi (PREFIX - như dấu âm) hay một toán tử 2 ngôi (EXPR).
func (a *ASTNode) Eval() (float64, error) {
if a == nil {
return 0, nil
}
switch a.Type {
case LITERAL:
return strconv.ParseFloat(a.Value, 64)
case PREFIX:
if a.Value == "negate" {
val, err := a.Right.Eval()
if err != nil {
return 0, err
}
return -val, nil
}
case EXPR:
// Đệ quy tính kết quả của vế trái và vế phải trước
leftVal, err := a.Left.Eval()
if err != nil {
return 0, err
}
rightVal, err := a.Right.Eval()
if err != nil {
return 0, err
}
// Sau khi có kết quả hai vế thì thực hiện các phép toán tương ứng
switch a.Value {
case "+":
return leftVal + rightVal, nil
case "-":
return leftVal - rightVal, nil
case "*":
return leftVal * rightVal, nil
case "/":
return leftVal / rightVal, nil
default:
return 0, fmt.Errorf("unknown operator: %s", a.Value)
}
}
return 0, fmt.Errorf("invalid AST node type: %s", a.Type)
}Logic ở đây rất trực quan. Nếu là số, nó sẽ trả về chính nó. Nếu là phép toán, nó sẽ ép vế trái và vế phải tự gọi đệ quy để tính ra một con số cụ thể trước, rồi mới cộng hai con số đó lại với nhau.
Lắp ghép thành ứng dụng CLI
Mảnh ghép cuối cùng là một hàm main để khởi chạy chương trình. Chúng ta sẽ tạo một vòng lặp REPL (Read-Eval-Print Loop) để liên tục nhận một biểu thức chứa khoảng trăng (như 1 + 4 * 2) từ bàn phím, chúng ta sử dụng bufio.Scanner thay vì fmt.Scanf().
func main() {
scanner := bufio.NewScanner(os.Stdin)
for {
if scanner.Err() != nil {
fmt.Println("Error reading input:", scanner.Err())
break
}
fmt.Print(">> ")
// đọc toàn bộ chuỗi đến khi nhấn Enter
if !scanner.Scan() {
break
}
source := scanner.Text()
source = strings.TrimSpace(source)
if source == "" {
continue
}
if source == "exit" {
break
}
// 1. Phân tích từ vựng
lexer := lexer.New(source)
// 2. Dựng cây cú pháp mới
p := parser.NewParser(lexer)
ast, err := p.Parse(0)
if err != nil {
fmt.Println("Error parsing:", err)
continue
}
// 3. Đánh giá và tính toán kết quả
result, err := ast.Eval()
if err != nil {
fmt.Println("Error evaluating:", err)
continue
}
// In ra kết quả với chính xác 2 chữ số thập phân
fmt.Printf("%.2f\n", result)
}
}Lời kết
Mình đã từng viết một chương trình để thông dịch và giải quyết các biểu thức toán học dạng LaTeX bằng Java sử dụng thuật toán này, và kết quả nó hoạt động ngoài mong đợi.
Pratt Parser là một thuật toán cực kỳ linh hoạt. Kiến trúc của nó cho phép bạn dễ dàng thêm, bớt các toán tử, xử lý tính kết hợp (associativity), hoặc thậm chí tự tạo ra một bộ syntax độc quyền của riêng bạn cũng được nuôn 🐧.
Mặc dù trong bài viết này, chúng ta mới chỉ dừng lại ở việc dựng cây AST và thực hiện các phép tính cơ bản (Evaluator), nhưng chừng đó là đủ để làm nền tảng cho những dự án phức tạp hơn như viết một trình thông dịch (Interpreter) hoàn chỉnh.
Chúc các bạn lập trình vui vẻ!